Решение
Специалисты «Интеллект Софт» в области искусственного интеллекта начали с анализа процессов заказчика и сбора данных. Сначала мы определили перечень госуслуг, а для каждой услуги составили точный список скан-копий документов, которые могут быть приложены в соответствии с требованиями регламентов. Также отметили, какие из них прикрепляются к заявке в электронном виде. Изучили частоту, с которой встречается каждый из документов. Кроме того, были изучены сотни образцов бланков, включая сканы и фотографии разного качества. Часть документов была заполнена от руки. Такие документы исключили из распознавания, в рамках задачи нас интересовало распознавание только бланков с фиксированной структурой, которые бы обеспечили высокий процент качества распознавания. Также исключили документы, которые встречаются крайне редко, т.к. разработка и поддержка механизмов распознавания для них нерентабельная для заказчика. По итогам составили таблицу с результатами анализа услуг и документов.
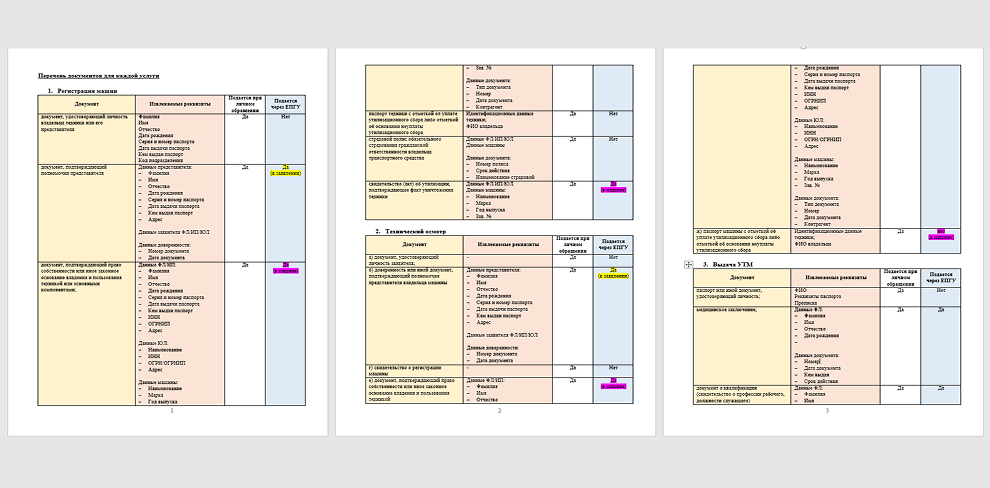
В результате анализа мы определили и согласовали с заказчиком список бланков для распознавания и обработки по каждой госуслуге.
На следующем этапе специалисты «Интеллект Софт» приступили к разработке стратегии создания обучающей выборки. В связи с тем, что использование реальных бланков было невозможно из-за конфиденциальности данных, команда приняла решение создать синтетический датасет, максимально приближенный к реальным условиям. Для этого были разработаны шаблоны бланков, имитирующие различные форматы и типы реквизитов. Затем с помощью алгоритмов аугментации данных (и фреймворка Albumentations) были созданы тысячи вариаций этих бланков: применялись искажения, изменения освещения, добавление шумов, размытие и другие эффекты, чтобы имитировать реальные условия съемки или сканирования.

После создания датасета команда приступила к разработке модуля распознавания. Наши эксперты в ИИ приступили к проведению экспериментов и подбору наиболее эффективного инструмента для решения задачи. Были рассмотрены различные фреймворки выполнения задач сегментации изображений и распознавания текста. В результате проведенных экспериментов наилучшие результаты для распознавания бланков показала связка фреймворков Detectron2 и EasyOCR.
В результате решение задачи распознавания бланка было решено разделить на несколько шагов:
Для многостраничного документа – разделение его на отдельные страницы для распознавания.
Поиск на снимке документа и его границ и определение типа найденного документа или документов.
Определение угла поворота документа и выравнивание документа строго вертикально (в т.ч. если документ был расположен боком или вверх ногами).
Проведение сегментации полей для конкретного типа документа. Для каждого типа документа выполнено обучение отдельной модели. Использование OCR-решения для распознавания текста в сегментированных полях.
Дополнительная валидация и обработка распознанного текста, обогащение данных и исправление синтаксических ошибок.
Интеграция модуля в существующую платформу обработки заявок была выполнена через API, что позволило системе автоматически передавать распознанные данные в следующие этапы обработки. В результате последующей опытной эксплуатации модуль достиг высокой точности и был готов к промышленной эксплуатации. А универсальная архитектура решения позволяет расширять в перспективе его применение для новых типов бланков и услуг.